

About me
My name is Yue Zhao* (赵岳 in simplified Chinese). I am a Postdoctoral Scholar at Stanford University, advised by Prof. Ehsan Adeli. I am affiliated with Stanford Translational AI (STAI) in Medicine and Mental Health and Stanford Vision and Learning Lab. I recently got my PhD from the University of Texas at Austin, supervised by Prof. Philipp Krähenbühl. I obtained my MPhil's degree from Multimedia Laboratory at the Chinese University of Hong Kong, supervised by Prof. Dahua Lin. More previously, I got my Bachelor's degrees from Tsinghua University. My research interests are in computer vision, with an emphasis on video analysis and understanding. I am currently interested in (1) video compression in pursuit of visual Intelligence, (2) understanding long-form streaming videos, and (3) learning executable actions from videos. I am a recipient of the 2024-2025 NVIDIA Graduate Fellowship.
News
[Dec 16, 2025] One tech report on quantization is on arXiv. A supplementary blog post is here.
[Oct 21, 2025] RayZer won ICCV 2025 Best Student Paper Honorable Mention!
[Oct 16, 2025] I am selected as a NeurIPS 2025 "Reviewer : Top Reviewer"!
[Jan 22, 2025] BSQ and ISM are accepted to ICLR 2025!
[Jun 11, 2024] One tech report on generic visual tokenizer is on arXiv.
[Jun 07, 2024] LaViLa (CVPR 2023) wins an Egocentric Vision (EgoVis) 2022/2023 Distinguished Paper Award!
[May 01, 2024] 🏳️🌈⃤ VideoPrism accepted to ICML!
[Apr 20, 2024] Our positive-congruent training paper accepted by TPAMI (finally)!
[Feb 26, 2024] One paper accepted to CVPR 2024. See you in Seattle this summer!
[Feb 20, 2024] One tech report on foundational video encoder is on arXiv. It is fueled by VIIT's captions.
[Jan 11, 2024] One tech report on video instruction tuning (VIIT) is available on arXiv.
[Dec 08, 2023] I am awarded the 2024-2025 NVIDIA Graduate Fellowship. Thank you NVIDIA!
[Jun 19, 2023] We won EPIC-Kitchens 2023 Action Recognition and Multi-Instance Retrieval Challenges! I gave a talk on the winning solution at the workshop.
[Feb 28, 2023] One paper accepted to CVPR 2023 as Highlight. See you in Vancouver this summer!
[Aug 07, 2022] One paper accepted to ECCV 2022.
[May 16, 2022] One tech report on positive-congruent training is available on arXiv.
[Mar 28, 2022] One paper accepted to CVPR 2022 as Oral.
[Aug 20, 2021] Had a wonderful summer at AWS in Seattle.
[Mar 09, 2020] Two papers accepted to CVPR 2020 (1 oral + 1 poster).
[Aug 02, 2019] The extended version of our ICCV 2017 work has been accepted by IJCV.
[Jun 18, 2019] We launch MMAction, a versatile toolbox for action understanding based on PyTorch. v0.1.0 is now online!
Selected Preprints
Spherical Leech Quantization for Visual Tokenization and Generation
Yue Zhao, Hanwen Jiang, Zhenlin Xu, Chutong Yang, Ehsan Adeli, Philipp Krähenbühl
arXiv:2512.14697 [cs.CV]
[pdf]
[blog]
[X]
[project page]
[code for generation]
[code for compression]
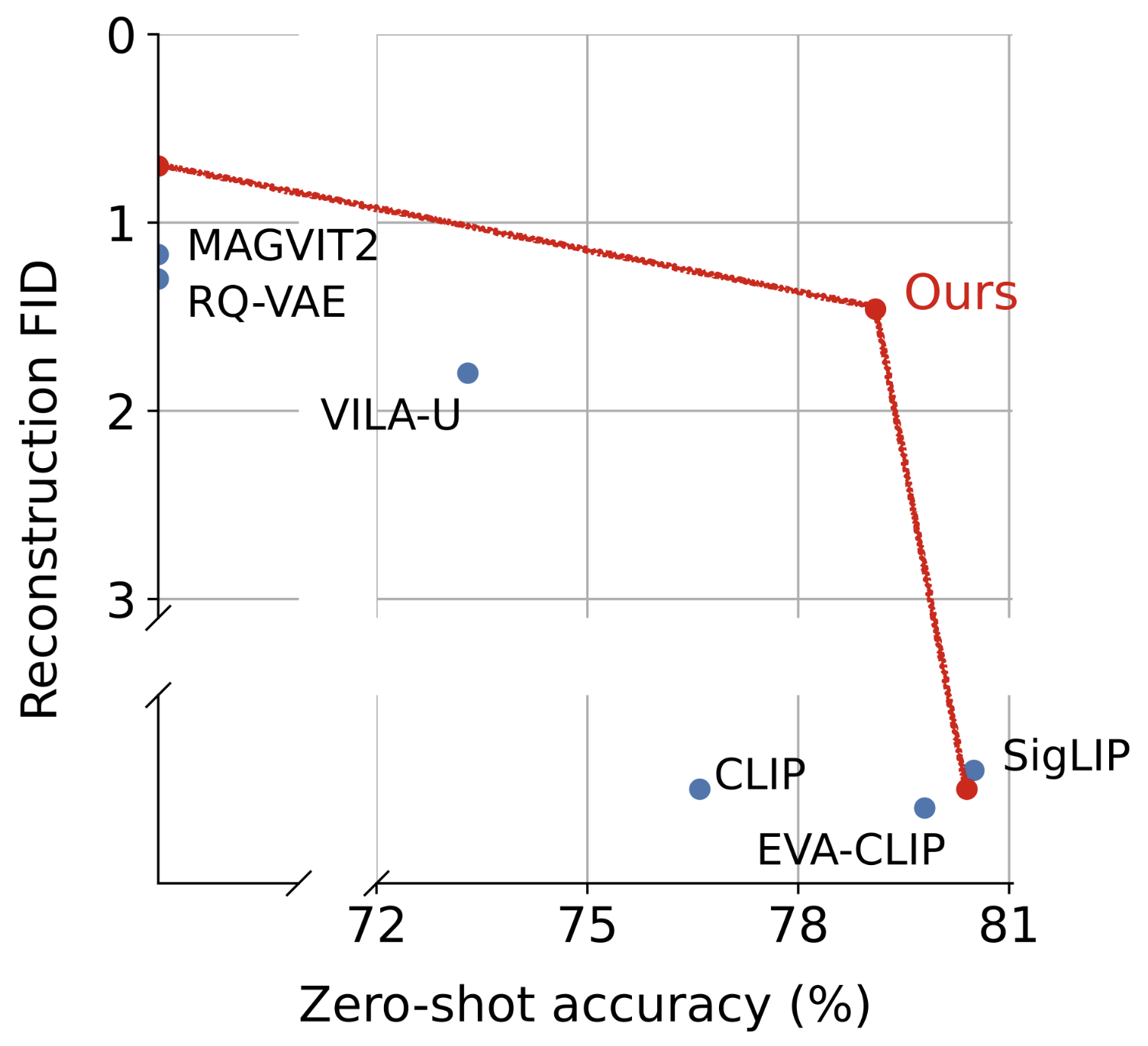
QLIP: Text-Aligned Visual Tokenization Unifies Auto-Regressive Multimodal Understanding and Generation
Yue Zhao, Fuzhao Xue, Scott Reed, Linxi Fan, Yuke Zhu, Jan Kautz, Zhiding Yu, Philipp Krähenbühl, De-An Huang
arXiv:2502.05178 [cs.CV]
[pdf][project page][code]
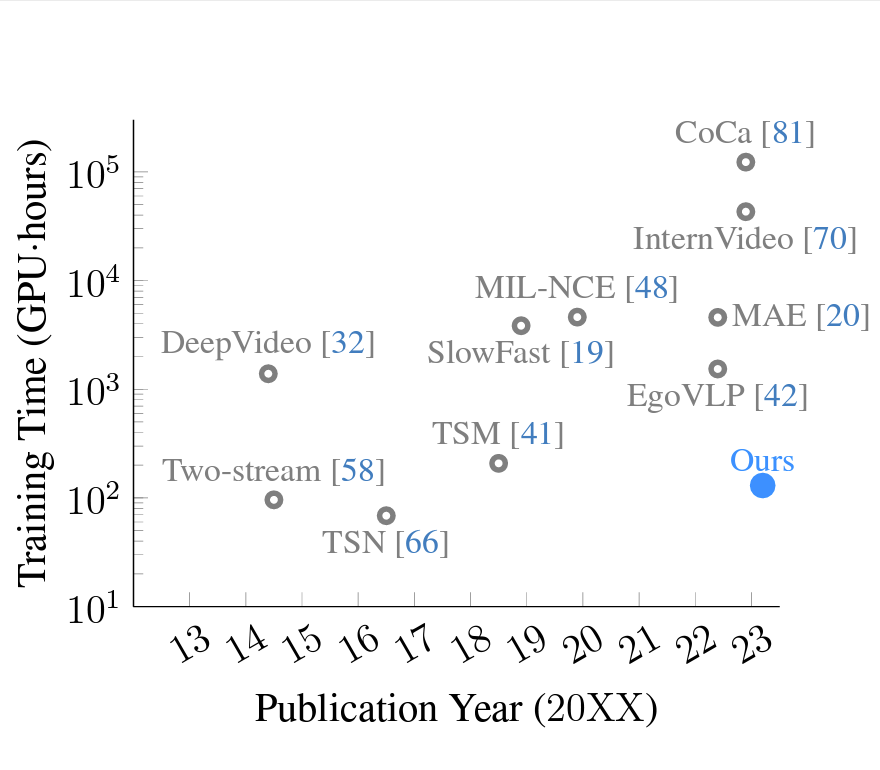
Training a Large Video Model on a Single Machine in a Day
Yue Zhao, Philipp Krähenbühl
arXiv:2309.16669 [cs.CV]
Winner of the EPIC-Kitchens 2023 Action Recognition and Multi-Instance Retrieval Challenges at CVPR 2023.
Invited talk at 11th EPIC Workshop at CVPR 2023
[pdf][code][tech report]
Selected Publications

One-Minute Video Generation with Test-Time Training
Karan Dalal*, Daniel Koceja*, Gashon Hussein*, Jiarui Xu*, Yue Zhao†, Youjin Song†, Shihao Han, Ka Chun Cheung, Jan Kautz, Carlos Guestrin, Tatsunori Hashimoto, Sanmi Koyejo, Yejin Choi, Yu Sun, Xiaolong Wang
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Invited keynote talk at The Workshop on Test-time Scaling for Computer Vision (ViSCALE) at CVPR2025
[pdf][project page][code]
[poster]
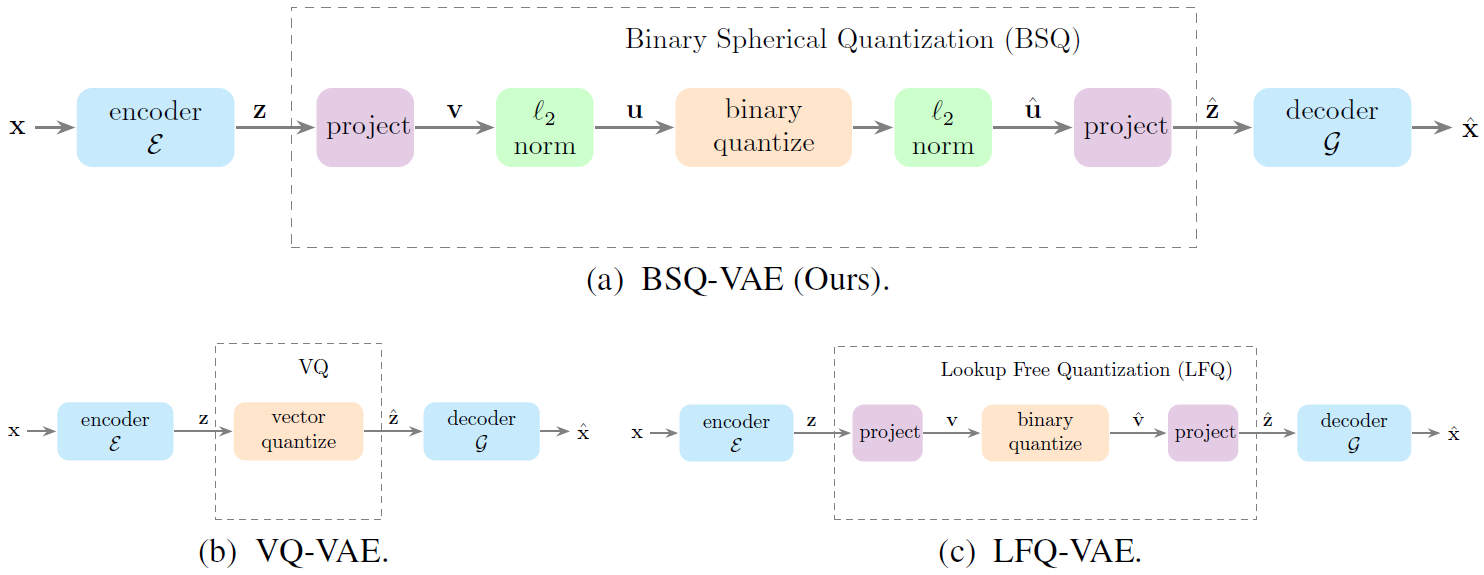
Image and Video Tokenization with Binary Spherical Quantization
Yue Zhao, Yuanjun Xiong, Philipp Krähenbühl
International Conference on Learning Representations (ICLR), 2025
[pdf][code]
[poster]
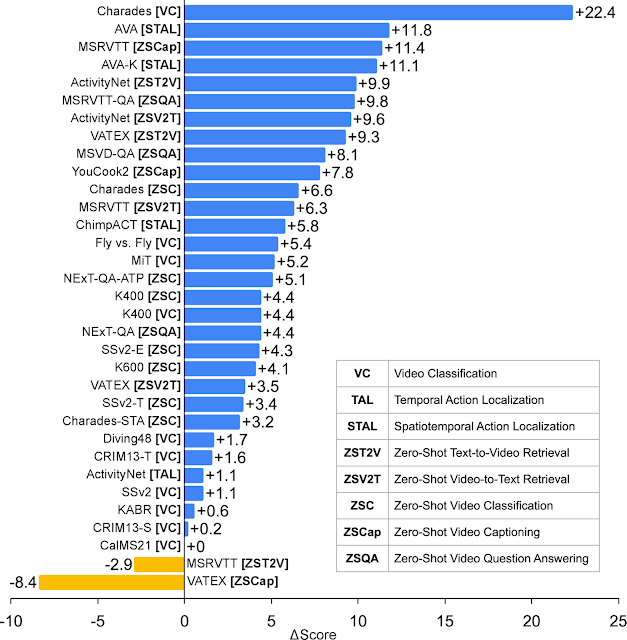
VideoPrism: A Foundational Visual Encoder for Video Understanding
Long Zhao*, Nitesh B. Gundavarapu*, Liangzhe Yuan*, Hao Zhou*, ..., Yue Zhao, ..., Mikhail Sirotenko+, Ting Liu+, Boqing Gong+
International Conference on Machine Learning (ICML), 2024
[arXiv]
[Blog]
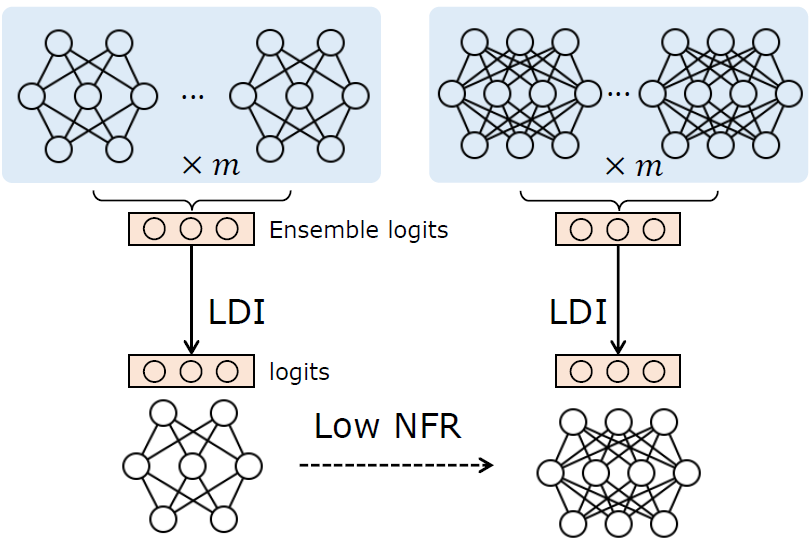
ELODI: Ensemble Logit Difference Inhibition for Positive-Congruent Training
Yue Zhao, Yantao Shen, Yuanjun Xiong, Shuo Yang, Wei Xia, Zhuowen Tu, Bernt Schiele, Stefano Soatto
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI), 2024
[arXiv][code]
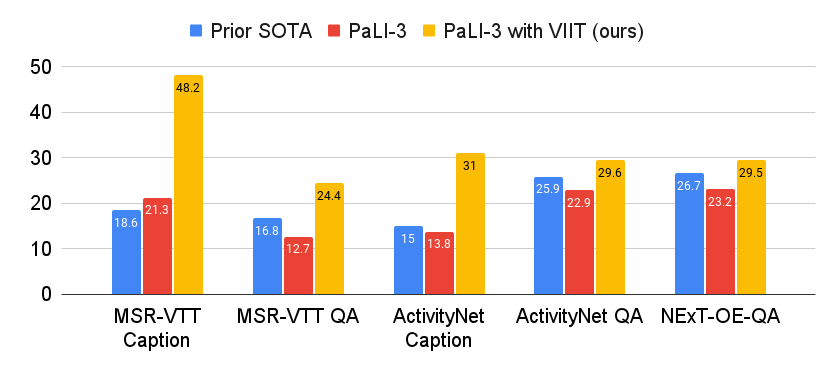
Distilling Vision-Language Models on Millions of Videos
Yue Zhao, Long Zhao, Xingyi Zhou, Jialin Wu, Chun-Te Chu, Hui Miao, Florian Schroff, Hartwig Adam, Ting Liu, Boqing Gong, Philipp Krähenbühl, Liangzhe Yuan
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2024
[arXiv]
[project page]
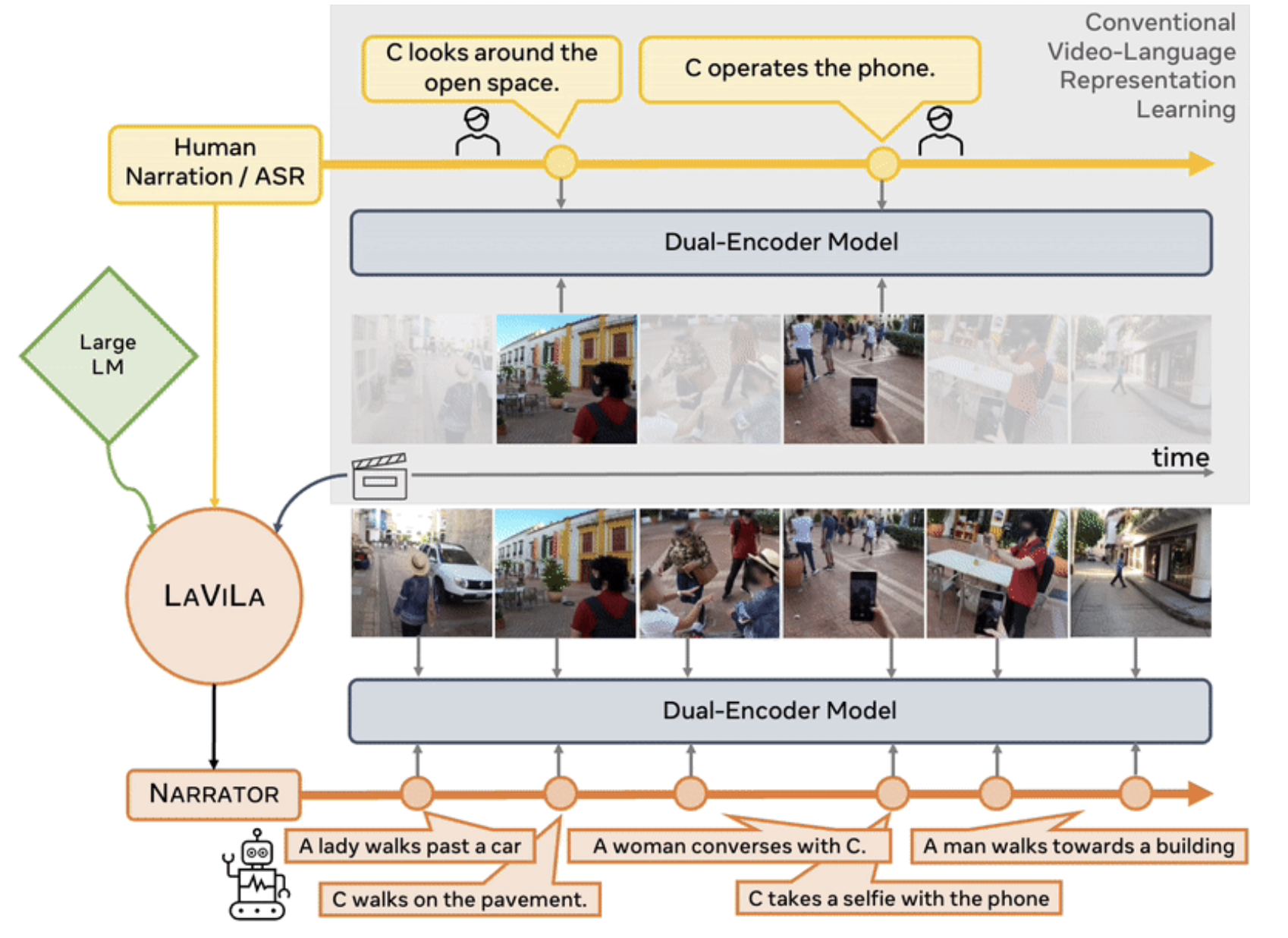
Learning Video Representations from Large Language Models
Yue Zhao, Ishan Misra, Philipp Krähenbühl, Rohit Girdhar
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
(Highlight, top-2.5%)
Invited talk at Joint International 3rd Ego4D and 11th EPIC Workshop
Egocentric Vision (EgoVis) 2022/2023 Distinguished Paper Award
[arXiv]
[code]
[project page]
[demo]
[colab]
[video (~8min)]
[poster]
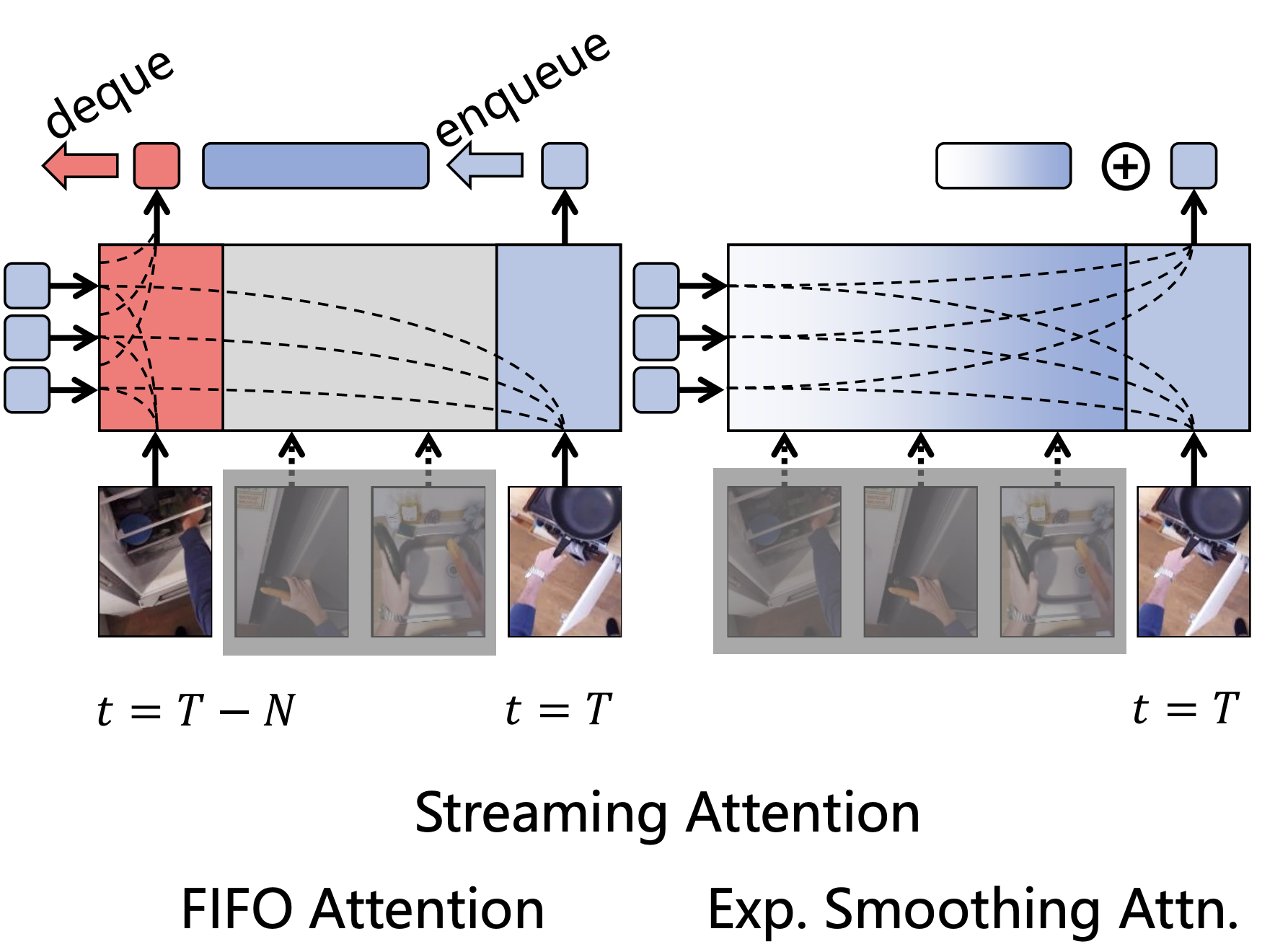
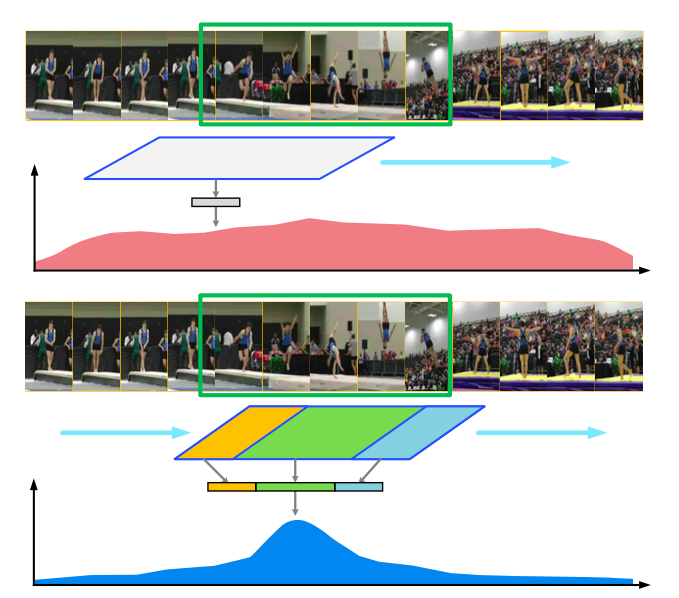
Real-time Online Video Detection with Temporal Smoothing Transformers
Yue Zhao, Philipp Krähenbühl
European Conference on Computer Vision (ECCV), 2022
[arXiv]
[code]
[poster]

Revisiting Skeleton-based Action Recognition
Haodong Duan, Yue Zhao, Kai Chen, Dahua Lin, Bo Dai
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2022 (Oral, top-4.2%)
[arXiv]
[code]
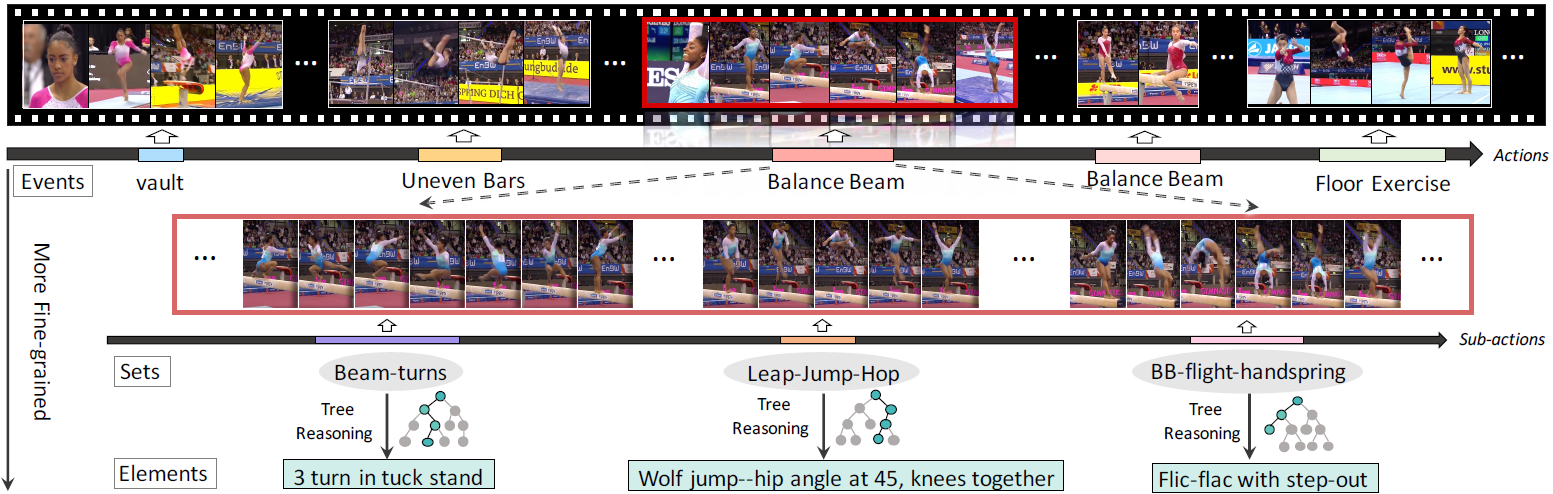
FineGym: A Hierarchical Video Dataset for Fine-grained Action Understanding
Dian Shao, Yue Zhao, Bo Dai, Dahua Lin
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020 (Oral, top-5.0%).
[arXiv][project page]
Temporal Action Detection with Structured Segment Networks
Yue Zhao, Yuanjun Xiong, Limin Wang, Zhirong Wu, Xiaoou Tang, Dahua Lin
International Conference on Computer Vision (ICCV), 2017.
[pdf]
[arXiv]
[IJCV version]
[code]
[project page]
Education Experience

The University of Texas at Austin, TX, USA
August 2020 - August 2025
Ph.D. in Computer Science.

The Chinese University of Hong Kong, HK SAR, China
August 2017 - July 2020
M.Phil. in Information Engineering.

Israel Institute of Technology (Technion), Haifa, Israel
July 2016 - August 2016
Visiting Student of Summer School of Engineering and Science, fully funded by Technion.

Department of Electronic Engineering, Tsinghua University, Beijing, China
August 2012 - July 2016
Bachelor of Engineering, magna cum laude.
School of Economics and Management, Tsinghua University, Beijing, China
August 2013 - July 2016
Bachelor of Science (Second Degree) in Economics.

Department of Information Technology and Electrical Engineering (D-ITET), Swiss Federal Institute of Technology(ETH), Zürich, Switzerland
September 2014 - Feburary 2015
Mobility student fully funded by China Scholarship Council (CSC).
Professional Experience

NVIDIA Research, Santa Clara, CA, USA
May 2024 - August 2024
Research Scientist Intern

Google Research, Venice, CA, USA
May 2023 - August 2023
Student Researcher

FAIR Labs, New York, NY, USA
May 2022 - August 2022
Research Scientist Intern

Amazon Web Services, Seattle, WA, USA
June 2021 - August 2021
Applied Scientist Intern
Multimedia Laboratory, The Chinese University of Hong Kong, HK SAR, China
September 2016 - August 2017, July 2015 - September 2015
Junior Research Assistant
Other projects

People tracking using RGB-D videos.
An undergraduate-level class project on people detection and tracking from RGB-D data collected by Kinect. [demo]